

WHERE CLINICAL KNOWLEDGE LIVES IN EHR FOUNDATION MODELS
Static vs contextual token embeddings from 1M patient histories in the THIN UK database
An EHR foundation model trained on a million primary-care timelines — with no drug–indication labels — recovers known pharmacology from co-occurrence alone, and attention sharpens it into a drug–disease geometry that points toward novel therapeutic uses.
KEY FINDINGS
- Self-supervised masked-language modelling on routine healthcare records recovers known pharmacological relationships — with no drug–indication labels used during training.
- The static embedding table alone reaches Precision@5 = 30% (18× the random baseline): co-occurrence structure across 1M patient timelines organises clinical codes by pharmacological function.
- Contextual attention amplifies the signal by 30% relative (39% vs 30%): six transformer layers compose multi-hop co-occurrence into a coherent drug–disease geometry.
- That emergent drug–indication geometry opens a direct path to identifying novel therapeutic uses for known drugs — surfacing latent relationships invisible to curated databases.
- Cross-vocabulary token embeddings are natural candidates for a joint latent space with biomedical knowledge graphs, bridging real-world-data evidence with curated biology for hypothesis-driven repurposing.
Research poster · chAIron SA × Cegedim Health Data × Bern University · presented at Swiss Biotech Day 2026 — Basel · validated against the Open Targets knowledge graph.
Presented: May 2026·Last updated: 11 June 2026
- Data
- THIN UK (Cegedim)
- Training cohort
- 1M patient timelines
- Full database
- 22.6M patients · ~2.5B events
- Vocabulary
- 58,800 tokens · 5 types
- Model
- 6-layer transformer · 256-d · BERT-MLM
- Prediction tasks
- 8 clinical onset / initiation
- Retrieval validation
- Drug→indication · Open Targets KG
- Headline result
- P@5 30% → 39% (23× random)
BACKGROUND
Electronic health records capture longitudinal patient histories — diagnoses (READ / ICD), prescriptions (ATC), lab results and clinical encounters — the richest real-world-evidence base in medicine. EHR foundation models pretrained on sequences of these clinical events learn dense vector representations of patients and clinical codes without any labelled data, mirroring the success of large language models in natural language processing.
These models produce two distinct levels of representation. Static token embeddings are fixed lookup vectors — one per clinical code — trained as model inputs via masked language modelling; they capture population-level co-occurrence statistics across millions of timelines. Contextual embeddings are transformer outputs that encode how each token is used within a specific patient context, refined through multi-head self-attention that composes clinical relationships dynamically.
Frozen foundation-model representations transfer effectively to downstream tasks: a lightweight MLP probe trained on fixed patient embeddings reaches strong performance with far fewer labels than supervised training from scratch. This work demonstrates label-free pretraining followed by linear evaluation across eight clinical onset and initiation tasks on 1M THIN UK primary-care timelines.
Where exactly does clinical semantic knowledge reside in a pretrained EHR foundation model? Does pharmacological signal emerge from the static input embeddings — reflecting lexical co-occurrence — or does it require contextual processing through attention layers to compose multi-hop clinical relationships?
DATA & ARCHITECTURE
The model is pretrained on 1M patient timelines sampled from the THIN UK healthcare database (22.6M patients; ~2.5B longitudinal events in total). The vocabulary spans 58,800 clinical tokens across five code types, all sharing a single 256-d embedding space; tokenisation follows the CEHR-BERT scheme with Artificial Time Tokens.
- READ diagnoses — 51K codes, 20 chapters
- ATC drugs — 3.5K codes
- LAB results · HX history · MED molecules
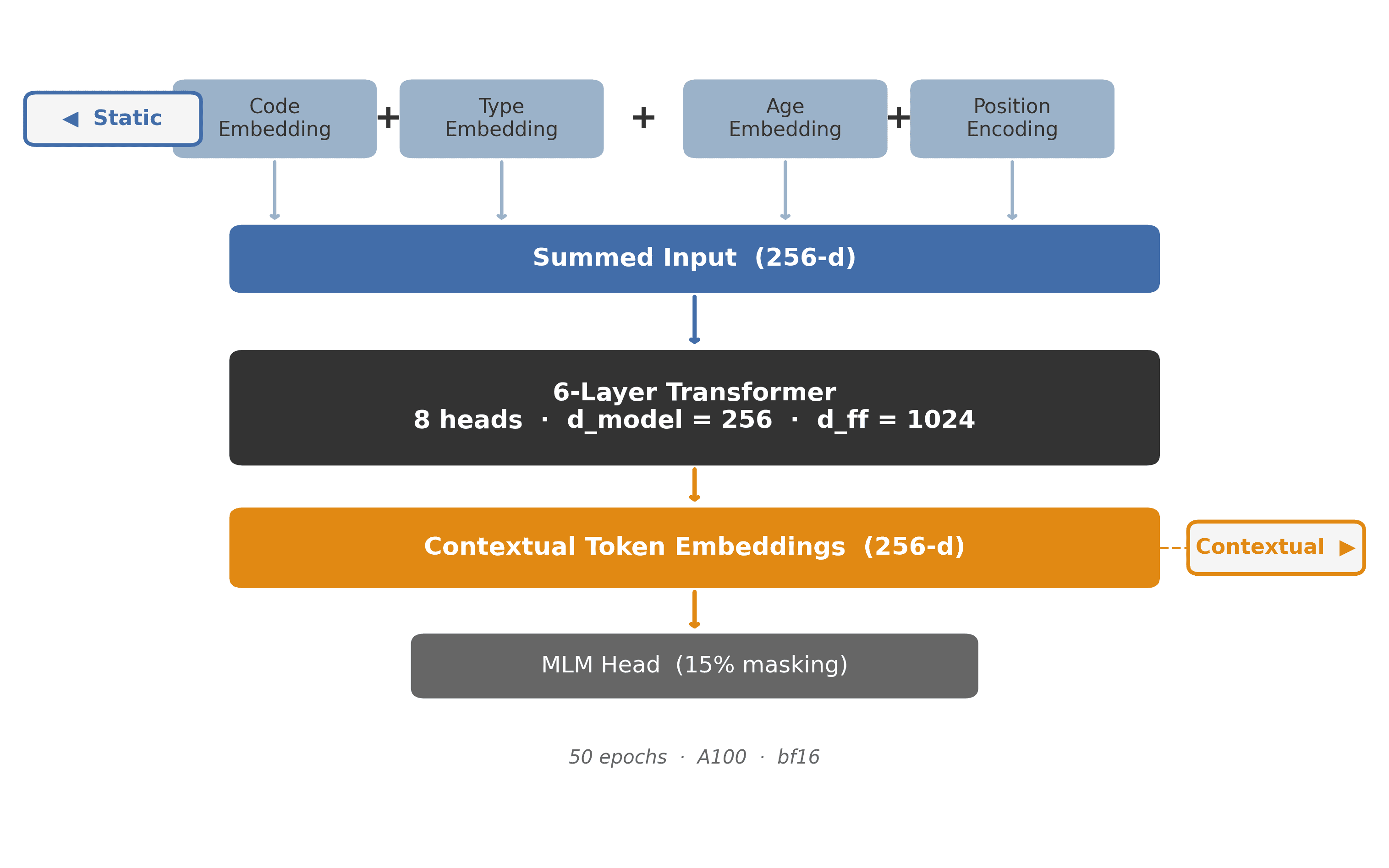
CLINICAL PREDICTION
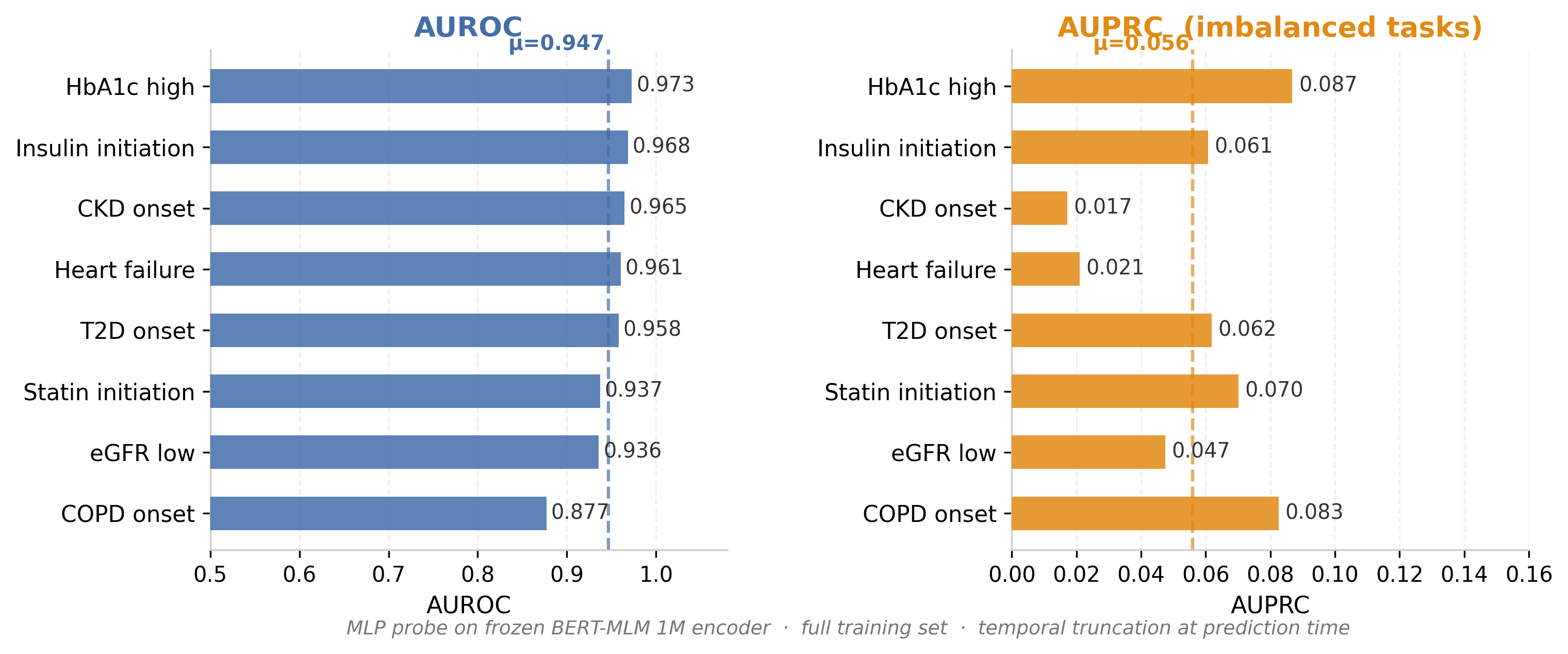
An MLP probe (two hidden layers) is trained on top of the frozen BERT-MLM encoder to predict eight clinical outcomes: CKD onset, COPD onset, low eGFR, elevated HbA1c, heart failure, insulin initiation, statin initiation and T2D onset. Patient timelines are strictly truncated at the prediction time point before encoding, eliminating any risk of leakage from future events.
AUROC ranges from 0.877 to 0.973 (mean 0.947), showing that the self-supervised representations carry strong discriminative power for risk stratification. AUPRC values are intentionally modest (0.028–0.091) because all eight tasks involve rare events in real-world primary care. Critically, no clinical labels were used during pretraining — all predictive signal emerges from 1M timelines of routine EHR data.
TWO LEVELS OF LEARNED KNOWLEDGE
To isolate the contribution of contextual processing, both embedding types are extracted for the same 20 drugs and evaluated independently on the drug–indication retrieval task. This separates the signal in the vocabulary's co-occurrence structure (static) from the compositional knowledge built by attention layers (contextual), enabling a direct quantitative comparison of what each representation level encodes about pharmacology.
STATIC EMBEDDING
The code lookup table E[token_id] — a fixed 256-d vector per token, identical regardless of patient context. Trained as a model input via masked-language-modelling backpropagation. Encodes population-level co-occurrence: codes that frequently appear together across 1M timelines embed nearby.
CONTEXTUAL EMBEDDING
The transformer output for a token, averaged across all its occurrences in 100K patients. Encodes how the token is used in clinical context — refined through 6 layers of multi-head self-attention that compose relationships between codes within each patient timeline.
Both representations are evaluated against Open Targets (approved drug–indication pairs, ChEMBL phase ≥ 3). For each drug the five nearest READ diagnosis codes are retrieved by cosine similarity and matched to known indications via an ATC → ChEMBL → EFO → READ-prefix mapping.
DRUG–INDICATION RETRIEVAL
For 20 drugs spanning antidiabetic, cardiovascular, respiratory and neurological areas, the top-5 nearest READ diagnosis codes are retrieved by cosine similarity and validated against Open Targets ground truth (Precision@5). The random baseline is P@5 = 1.7% — chance retrieval from the full 58,800-token vocabulary.
Static embeddings achieve P@5 = 30.0% (18× random): co-occurrence structure alone spontaneously organises the clinical vocabulary by pharmacological function, without any drug–indication labels. Performance varies — common drugs with strong signals (glyceryl trinitrate, levothyroxine) exceed 60%, while sparse or ambiguous ones score lower. Contextual processing raises the mean to P@5 = 39.0% (23× random) — a 30% relative gain — with the largest improvements where attention can compose multi-hop paths: drug → co-prescribed counterparts → shared diagnoses.
WHAT CHANGES WITH CONTEXT?
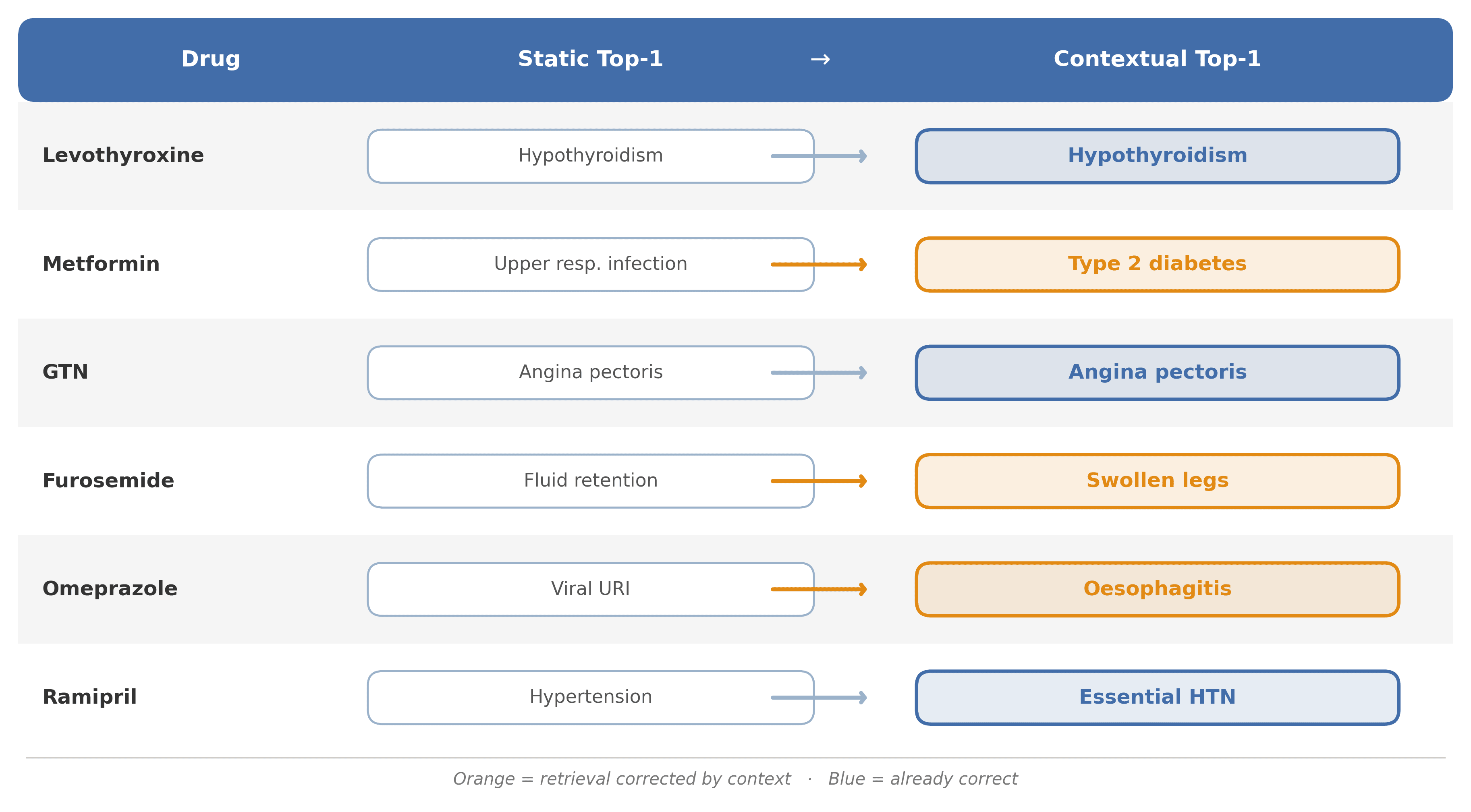
Comparing the single nearest READ diagnosis in the static vs contextual space reveals where attention adds pharmacological information beyond raw co-occurrence. Context corrects systematic errors: Metformin's static top-1 is upper respiratory infection — a co-prescription artefact of broad antibiotic use — while contextual processing correctly retrieves Type 2 Diabetes; Furosemide shifts from generic fluid retention to the more specific swollen legs.
Context also sharpens already-correct signals: GTN (angina), Omeprazole (oesophagitis) and Ramipril (hypertension) were ranked correctly statically and become stronger contextually. The mechanism: attention layers traverse drug → co-prescribed drugs → shared diagnoses, amplifying true indication signal while suppressing spurious co-occurrence.
AGGREGATE KG VALIDATION
Across the 20-drug set, contextual embeddings improve every retrieval metric over static, and both sit far above the random baseline — confirming at aggregate level that self-supervised co-occurrence learning, then attention-based composition, organises the clinical vocabulary by pharmacological function entirely without drug–indication labels.
| METRIC | STATIC | CONTEXTUAL | RANDOM |
|---|---|---|---|
| P@5 | 30.0% | 39.0% | 1.7% |
| P@10 | 28.5% | 29.0% | 3.3% |
| R@5 | 11.1% | 13.2% | — |
| R@10 | 15.8% | 16.0% | — |
EMBEDDING SPACE VISUALISATION
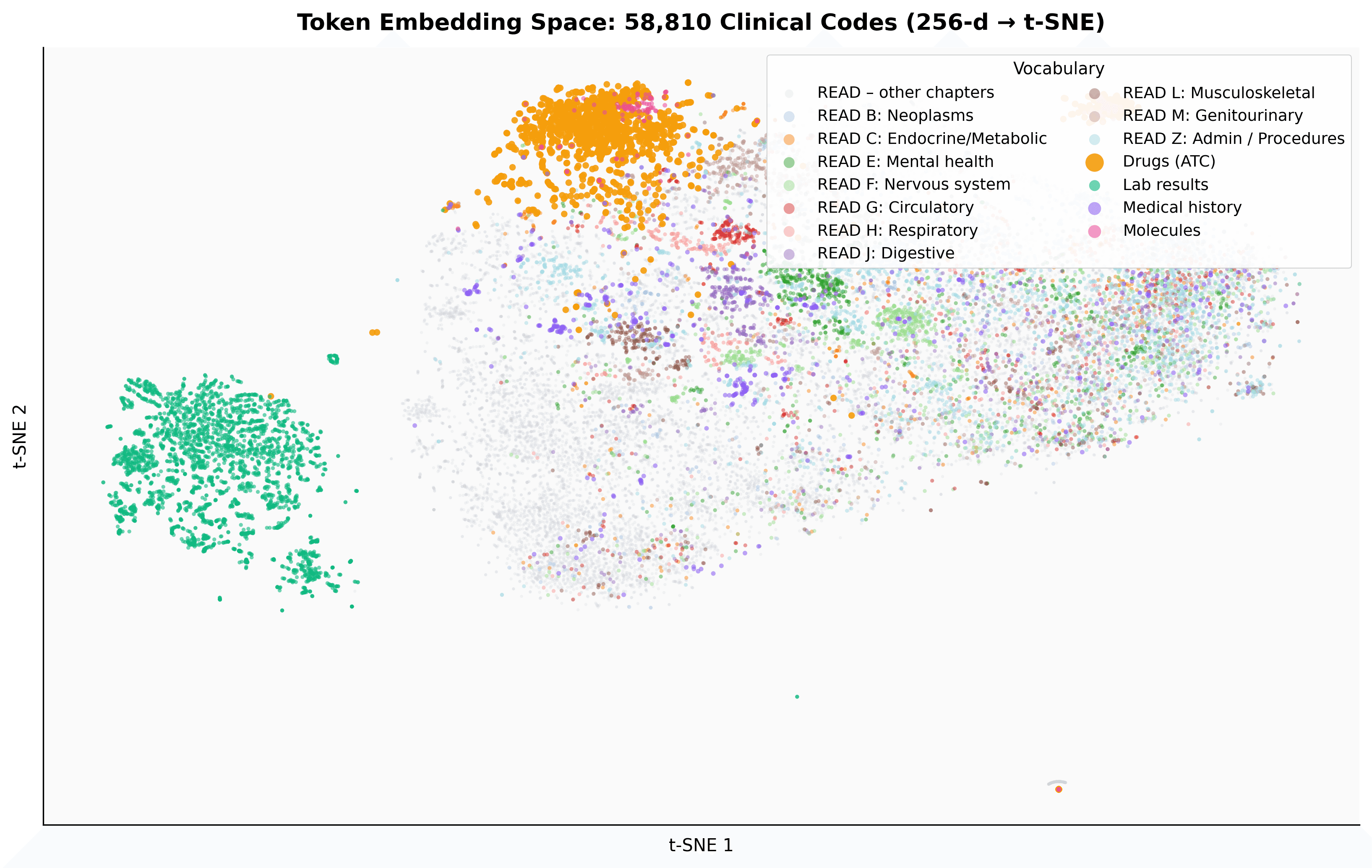
A t-SNE projection of 58,810 contextual embeddings, coloured by READ chapter and vocabulary type, shows that drugs (ATC), diagnoses and labs from the same specialty form mixed-vocabulary neighbourhoods — without any cross-vocabulary supervision. This emergent organisation is exactly the geometry that makes drug–indication retrieval possible.
WHY IT MATTERS
DRUG REPURPOSING
A label-free route to candidate indications for known drugs, grounded in population-scale EHR patterns rather than curated databases alone.
DISCUSS A REPURPOSING HYPOTHESISREAL-WORLD EVIDENCE TEAMS
Frozen FM embeddings transfer to clinical prediction with far fewer labels — a reusable representation across many downstream tasks.
DISCUSS AN RWE USE CASEKNOWLEDGE-GRAPH INTEGRATION
Cross-vocabulary embeddings are ready to join a biomedical knowledge graph, bridging RWD-derived signal with curated biology.
DISCUSS KG + RWE INTEGRATIONAUTHORS
Chief Scientific Advisor at chAIron SA; led the work and provided senior scientific review. Corresponding author — flavio.dormont@chairon.io.
LinkedInAI Products & Strategy at chAIron SA; led the data analytics behind the embedding and retrieval experiments.
LinkedInGlobal Head, Cegedim Health Data — the real-world-data partner providing the THIN UK database.
LinkedInTeam Lead of Biostatistics at Bern University; provided methodological guidance on the real-world-data analysis.
LinkedInFREQUENTLY ASKED QUESTIONS
A transformer pretrained, like a language model, on sequences of clinical events from electronic health records — diagnoses, prescriptions, labs and encounters. It learns dense vector representations of patients and clinical codes by self-supervision (here, masked-language modelling), with no task labels, and those representations transfer to many downstream clinical tasks.
Static embeddings are the fixed input lookup vectors — one per clinical code, identical regardless of context — and capture population-level co-occurrence. Contextual embeddings are the transformer outputs, which encode how a code is used within a particular patient timeline, composed through self-attention. This work measures how much clinical knowledge each level holds.
No. The model is trained purely by self-supervision on 1M patient timelines. Open Targets approved drug–indication pairs are used only afterwards, as an external ground truth, to validate what the embeddings already encode.
For each drug, the five nearest diagnosis codes in the embedding space are retrieved and checked against known indications. Precision@5 is the fraction of those five that are correct. Static embeddings reach 30% and contextual 39%, versus a random baseline of 1.7% — i.e. 18× and 23× chance.
The eight prediction tasks are rare-event, heavily class-imbalanced problems in routine primary care. AUROC stays high (mean 0.947) because the model ranks risk well, while AUPRC is necessarily modest (0.028–0.091) — the expected signature of imbalanced clinical tasks, not a weakness of the representation.
That is the motivating implication. Because the embedding geometry encodes drug–disease relationships learned from real-world patterns — including ones not curated in existing databases — it offers a principled starting point for hypothesis-driven drug repurposing, always validated by domain experts before any decision.
The THIN UK primary-care database, accessed under licence from Cegedim Health Data. Analyses run on de-identified records within the licensed environment; the model learns from event sequences, not patient identities. The full database covers 22.6M patients and ~2.5B events; this study sampled 1M timelines.
Scaling to the full THIN cohort (22.6M patients, 2.5B events); extending to adverse-event signals; exploring JEPA-style objectives for richer temporal representations; and building a joint EHR–knowledge-graph embedding space.
REFERENCES
- [1]Pang et al. (2021). CEHR-BERT. ML4H.
- [2]Li et al. (2020). BEHRT. Scientific Reports, 10:7155.
- [3]Ochoa et al. (2023). Open Targets. Nucleic Acids Research, 51:D1302.
- [4]Steinberg et al. (2025). CoMET. arXiv:2508.12104.
- [5]Rasmy et al. (2021). Med-BERT. npj Digital Medicine, 4:86.
RELATED
FROM REAL-WORLD EVIDENCE TO NOVEL THERAPEUTIC HYPOTHESES
Talk to us about applying mechanism-grounded, real-world-data methods to your asset — peer to peer.
BOOK AN INDICATION-STRATEGY CALLResearch collaboration: chAIron SA · Cegedim Health Data · Bern University. THIN UK data accessed under licence from Cegedim Health Data.